
This page describes the problem solving techniques used by the teams in HackOff 2008. But how do we know?
Teams downloaded the data file for each problem from the event web server and also used the web server to submit the 'token' when they solved the problem. After a correct token was accepted, the web server would prompt the team to 'show their work'. They could type in a description; copy and paste a shell command history; list URLs of web sites they used; and upload the source code of any programs they wrote. Of course this step was purely voluntary so if a team entered a one word answer like 'magic' then we really don't know how they did it - sorry.
Remember, this competition was about solving problems in a pragmatic way. It was perfectly allowable for teams to use off-the-shelf tools and libraries as well as web services - just like real life.
The original registration page for the HackOff event included a teaser question. The idea was that teams would decode the teaser data to reveal a 6 letter password that they would use on the night to connect to the wireless network at the competition venue. In practise we turned off all wireless security on the night because we couldn't find any settings that worked for everyone.
This is the original data for the teaser problem:
EFBBBF2C756FC9A5CA87CA8E642CC2A073C4B1C2A0C99FC99F6FC A9EC994C990C9A5C2A0C9AF64CB99756FCA87C68375C4B16C6CC7 9DCA8DC2A0C79DC9A5CA87C2A0C9B96FC99FC2A070C9B96FCA8D7 373C99064C2A0CA87C79DC9B9C994C79D73C2A0C79DC9A5CA870A
This problem was actually a lot simpler than most people thought. People generally recognised that the data was hexadecimal, so they imagined a series of steps something like this ...
And people were completely correct to assume that ... except there is no step 2.
So all that was required was to take pair of characters (such as the initial 'E' and the 'F' which follows it) and write them out as a single byte. For example, you could write that byte using this line of Perl:
print "\xEF";
Many people failed to recognise that the bytes are text - presumably because it's not ASCII text. However it is UTF-8 encoded Unicode text (the three initial bytes 0xEF, 0xBB and 0xBF form a UTF-8 Byte Order Mark or BOM) and can be converted to a readable form using this Perl program:
#!/usr/bin/perl
use strict;
use warnings;
my $data = 'EFBBBF2C756FC9A5CA87CA8E642CC2A073C4B1C2A0C99FC99F6FC'
. 'A9EC994C990C9A5C2A0C9AF64CB99756FCA87C68375C4B16C6CC7'
. '9DCA8DC2A0C79DC9A5CA87C2A0C9B96FC99FC2A070C9B96FCA8D7'
. '373C99064C2A0CA87C79DC9B9C994C79D73C2A0C79DC9A5CA870A';
print pack('H*', $data);
Which outputs this text:
,uoɥʇʎd, sı ɟɟoʞɔɐɥ ɯd˙uoʇƃuıllǝʍ ǝɥʇ ɹoɟ pɹoʍssɐd ʇǝɹɔǝs ǝɥʇ
Using 'print' to write UTF-8 characters to STDOUT won't work for everyone it depends on your terminal program being configured with an appropriate locale and it requires support for the funky upside-down characters in your terminal font. However, if the output was redirected to a file and the file opened in a web browser then it would be readable on most modern desktop systems (it even works in Lynx).
You can make your own upside-down text messages the same way we did - using this web site: http://www.revfad.com/flip.html
The first question on the night used this data file: 
and this hint:
In this case the data was an mbox format file containing a single email message purporting to be from Samuel Morse. The message had a file attachment of type text/plain, MIME encoded using Base64 encoding. The contents of the (decoded) attachment looked like this:
Dah Dit-Dit-Dit-Dit Dit / Dit Dit-Dit Dah-Dah-Dit Dit-Dit-Dit-Dit Dah / Dit-Dah-Dit-Dit Dit Dah Dah Dit Dit-Dah-Dit / Dit-Dit-Dit Dit Dah-Dit-Dah-Dit Dit-Dah-Dit Dit Dah / Dah Dah-Dah-Dah Dah-Dit-Dah Dit Dah-Dit / Dit-Dit Dit-Dit-Dit / Dit Dit-Dit-Dah-Dit Dah-Dah (etc)
The 'Dit's and 'Dah's are Morse code. Once decoded to plain text the message read:
The eight letter secret token is EFMSFZFJ. The remainder of this message is just useless filler. There really is no point decoding anything after this. In fact the first sentence was all you needed. Why are you still decoding this. There is nothing worth reading here. (etc)
The steps required to solve this one were:
The really quick and easy way to achieve step one was to open the mbox file with an email program, open the message and save its attachment. For step two, there are a number of online Morse code to ASCII converters however these generally required the 'Dit's and 'Dah's to be converted to '.' and '-' (a couple of quick substitutions in a text editor).
Team Amorphous were first to complete this problem. They extracted the attachment using the 'base64' utility from the coreutils package, converted to ./- with vi and sed then used an online service to translate to ASCII (after decoding the first few letters by hand to confirm they had the "Dit" and the "Dah" the right way round).
Team Orange were next. They used PHP's base64_decode function and str_replace function. Then used the same online service to translate to ASCII - despite one of their team members being a licensed ham radio operator (apparently the online service was quicker).
Team Cabbage were next. They used Perl's MIME::Base64 module to extract the attachment, and converted the characters using Emacs. Rather than using an online service they were able to translate the file using the 'morse' command-line utility from the bsdgames package.
The Terminators finished next. They used a different online service to translate to ASCII and didn't waste any time explaining how they extracted and massaged the data (although Perl and Vim are likely candidates).
Starsky & Hutch were the last to complete this problem. They took the unusual step of using an online service to extract the Base64 encoded attachment. They then used find-and-replace in a text editor (probably Kate) to massage the morse code and finally used the Convert::Morse Perl module to translate to ASCII.
The second question used this data file:
and this hint:
The file format this time was HTML although the 'interesting' data was plain text within <pre> tags. This is a snippet of the data:
Hafnium-1 Lithium-2 Tellurium-2 Praesodymium-1 Astatine-2 Neon-1 Thorium-1 Gadolinium-1 Promethium-1 Molybdenum-1 Neptunium-2 Zinc-1 Protactinium-2 Zinc-1 Platinum-1 Zinc-1 Promethium-1 Lead-1 Polonium-1 Polonium-1 Promethium-1 Neptunium-2 Plutonium-1 Curium-2 Technetium-1
The HTML file included detailed instructions for converting the strings of text-number pairs to binary bytes which would produce a PNG image of the required token. The first step of this challenge was mapping the element names (eg: 'Lead') to their chemical symbols (eg: 'Pb'). Once that was done, some bitwise manipulation of the ASCII codes was required to turn a pair of letter characters into one binary byte. Just to make things interesting, the source data used elements names with a mixture of American and British English spellings.
Once again, Team Amorphous were first to complete the challenge. They found a list of element names and chemical symbols via Google and wrote a Perl program to do the mappings and bit manipulations.
Team Cabbage shunned Google and returned to the bsdgames package for their list of chemical elements and symbols. One team member wrote a Perl program to convert the element name-number sequences to ASCII letter pairs, while another wrote a Perl program to do the bit manipulations required to turn letters pairs into bytes.
Team Orange found their element data via Google and wrote a PHP program to do the required conversions. After initially structuring their program to return the PNG data as an HTTP response, they switched to running it from the command line and writing the output to a file.
The Terminators also found their element data via Google and wrote a Perl program to convert it. Unlike the first three teams, they shunned Perl's bit manipulation operators (&, |, <<, etc) and instead converted the ASCII characters to hex strings and then used string manipulations to slice and dice the bits. Unfortunately they forgot that the result was still ASCII hex and wasted a bit of time trying to work out why their image viewer wouldn't read it. Eventually (after a bit of forehead slapping) they ran the hex data through Perl's pack() function and the solution was revealed.
Starsky & Hutch used the Chemistry::Elements module from CPAN for the element name to symbol mappings, but had to hard code around the spelling issues. They operated on the data in ASCII hex and used pack() to output as binary. Unfortunately it took them some time to realise they'd used 'h' instead of 'H' in their pack template so each byte had its nybbles swapped.
The third question used this data file:
and this hint:
The source ZIP file contained three CSV files and no instructions. The challenge was to take the text snippets (or 'banner fragments') from the first CSV file, re-order them and write them out to produce a (sideways) message similar to this:
## #
## #
#########################################
#########################################
#########################################
#########################################
## ## #
## ## #
##
##
##
##
##
##
## ## #
#########################################
#########################################
#########################################
#########################################
#########################################
## #
## ##
######################### #####
######################### ######
######################### ######
######################### #####
##
### #########
##### ########################
####### ##############################
##### ########################
### #########
Some analysis of the data was required to determine that each entry in the banner_fragment.csv file was unique, so clearly some of them would need to be used more than once. Each fragment was also identified by a unique 'frag_id' primary key. The fragment_sort_bin.csv file use the frag_id to associated each instance of a fragment with a set of three sort keys. Each sort key identifier in turn mapped to a record in the sort_bin.csv file.
To assemble the correct output, one fragment string must be extracted from banner_fragment.csv for each row in fragment_sort_bin.csv and all these rows must be sorted by the numeric values of sort_key_1, sub-sorted by sort_key_2 and sub-sub-sorted by sort_key_3.
Or to put it another way, if you were to slurp the three CSV files into tables in a database, you could produce the required output using this SQL:
SELECT f.secret_fragment FROM fragment_sort_bin fs JOIN banner_fragment f ON (fs.frag_id = f.frag_id) JOIN sort_bin s1 ON (fs.sort_key_1 = s1.sort_key) JOIN sort_bin s2 ON (fs.sort_key_2 = s2.sort_key) JOIN sort_bin s3 ON (fs.sort_key_3 = s3.sort_key) ORDER BY s1.bin, s2.bin, s3.bin;
Team Cabbage were surprised to find that although the bsdgames package had been used to generate the problem data, the package offered no handy tools for finding a solution. Despite this setback and despite taking a particularly circuitous route to a solution, they still managed to complete it ahead of arch rivals Team Amorphous. They started by writing a Perl program which slurped the contents of sort_bin.csv into a hash. Then they iterated through the lines of fragment_sort_bin.csv looking up each sort key in the hash and outputting lines with the sort keys replaced with the numeric values from the hash. The three numeric values were concatenated together (eg: 17, 53, 21 became '175321'). The output of this Perl program (a fragment identifier followed by one combined sort key) was then piped through the Linux sort utility to reorder the lines; then piped into 'cut' to strip off the sort key; then into a shell while/read loop which used grep to extract the matching row from banner_fragment.csv; followed by awk to extract just the banner fragment field. Amazingly it worked! In his writeup, the Team Cabbage scribe did admit that it would have been easier to do it in Postgres using 'COPY' to slurp in the CSV files.
Team Amorphous started out with a similar approach to Team Cabbage - writing a Perl program to slurp sort_bin.csv into a hash. Once they got that working they used the exact same technique to slurp banner_fragment.csv into another hash. Then they iterated through all the lines in fragment_sort_bin.csv, replacing each fragment and sort key identifier with the corresponding value from on of the two hashes. The rewritten lines were sent to STDOUT and piped through the command-line sort utility to produce the required output.
Team Orange were the only other team to complete this question within the allotted time. Their solution was essentially the same as the Team Amorphous solution except of course it was written in PHP. Rather than using the shell sort utility, the lines of substituted values were collected into a hash (PHP 'array') and ksort used to reorder the keys.
Starsky & Hutch plugged on valiantly with this question well after the contest winner had been announced. They were playing for pride and through their efforts they managed to escape the ignominy of a last-equal placing with Team Terminator. Their eventual solution was a Perl program using the now familiar 'slurp everything into hashes' approach and for a moral bonus point they even did their sort in Perl.
The fourth question used this data file:
and this hint:
The source ZIP file contained an HTML file, a CSS file and an Apache access log. When viewed in a browser, the HTML looked something like this:
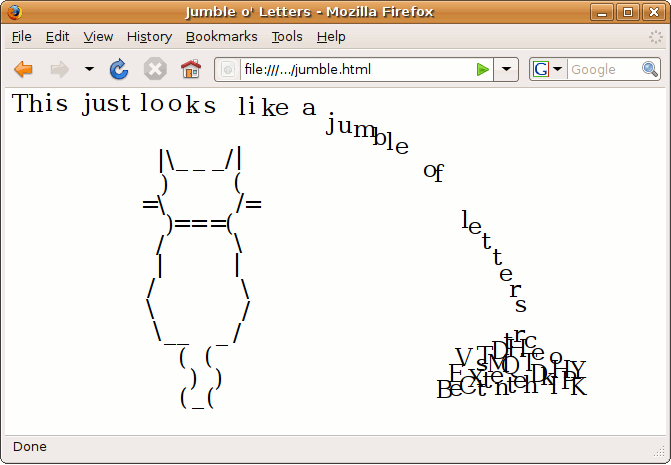
Each character in the HTML was individually positioned on the screen using CSS. The challenge (as detailed in comments in the CSS file) was to replace the CSS rules with an alternative set which placed the letters in different positions to spell out the solution. The alternative CSS was provided however the CSS selectors did not match the ID attributes in the HTML. To map the new CSS selectors to the correct IDs, it was necessary to do some analysis of the Apache server access log. Log entries could be paired up by looking at Referrer URLs and matching them to earlier requests from the same client IP address - one log entry would contain the document ID and the other would contain the CSS selector.
Only two teams completed this problem. Team Cabbage were first by over 10 minutes. They wrote a Perl program which did some ad hoc dissection of the log lines and used a hash to track the latest request from each IP address. The program produced a set of old to new selector mappings. Another Perl program read these mappings and updated the CSS file accordingly.
Team Amorphous used a Perl script to sort the log entries by IP address. A second Perl script picked out the mappings by matching consecutive log lines and output lines of the form 's/id053/bassetti/' - ie: the output was a sed script which was then used to rewrite the CSS file.
The final question used this data file: 
and this hint:
The source GIF file appeared to be a small photo of the Easter Island statues. A comment embedded in the image described a set of rules for updating each entry in the colour table based on its index. Where the index was a prime number the colour should be changed to red, where the index was an even number the colour should be changed to blue, in all other cases, the colour should be changed to white. Viewing the image with the rewritten colour table would reveal the solution.
The resident Python Ninja on Team Cabbage wrote a program using Python's 'Image' library to replace the entries in the source image's color palette. The program used a hard coded list of prime numbers which came from ... wait for it ... the bsdgames package! In parallel, the team's resident mathematics ninja used the Gimp to manually edit the colour table using only the power of his mind to identify the prime numbers. Needless to say, Python won.
The resident C Ninja on Team Amorphous downloaded the source code for the netpbm tools and hacked the source code for the giftopnm utility to apply the colour mapping rules on the fly (and even implemented his own function to identify primes). Choosing such a low-level approach had the obvious advantage of shaving milliseconds off the final run time compared to the Python solution. It had the more surprising advantage of taking less time to implement than the Python solution. Despite these advantages, Team Amorphous were unable to make up sufficient ground and finished in second place a few minutes after Team Cabbage submitted the winning answer.
If you've worked your way through the HackOff questions and would like to showcase your code, send a URL to Grant (email link below) and we'll add it here.
Thank you to everyone who took part in HackOff 2008. It was a fun evening and we're already looking forward to HackOff 2009.
Contact Grant McLean if you have any questions, corrections or other feedback.